
0. 들어가기 전
특정시각에 오픈하는 상품을 재고수보다 훨씬 많은 유저들이 구매하려 시도했을 때 어떻게 하면 OverSelling이 일어나지 않을까??
1. synchronized 붙이기
@Transactional
public synchronized OrderDto preCreate(Long userId, Long productId) {
// db에서 재고를 줄일 것
stockDbClient.decreasePreStock(productId);
// 주문 상태 성공으로 바꾸기
OrderDto dto = orderClient.successOrder(productId, userId, "GENERAL");
return dto;
}문제없이 잘 실행이 되었다.
하지만 synchronized는 나의 프로젝트에서 쓰기엔 치명적인 단점이 있다.
synchronized는 하나의 스레드만 접근이 가능하다는 조건이 바로 하나의 프로세스에서만 보장되는 특징이다.
그렇다면 scale-out으로 서버가 여러 대일 때 동시성이 보장되지 않는 치명적인 단점이 있다.
그래서 MySQL의 Lock을 사용해 보자
2. MySQL의 Lock
2-1. 비관적 락 (Pessimistic Lock) (적용 )
비관적 락은 데이터를 읽거나 수정할 때 해당 데이터에 대한 락을 설정하여 다른 트랜잭션이 해당 데이터를 변경하지 못하도록 한다.
"먼저 온 사람이 먼저 사용하는"방식이다.
한 트랜잭션이 특정 데이터에 접근하면 그 데이터에 대한 락을 설정하고, 다른 트랜잭션이 해당 데이터에 접근하려고 하면 락이 해제될 때까지 대기하게 된다. 이를 통해 동시성 문제를 해결하고 데이터의 일관성을 보장할 수 있다.
비관적 락에는 두 가지 종류의 락이 있다.
- Write Lock
- 데이터를 수정할 때 사용
- 한 트랜잭션이 Write Lock을 설정하면 다른 트랜잭션이 해당 데이터에 대한 읽기와 쓰기 모두 제한받는다.
- 해당 락이 해제될 때까지 대기해야 한다.
- Read Lock
- 데이터를 읽을 때 사용
- 한 트랜잭션이 Read Lock을 설정하면 다른 트랜잭션에서 해당 데이터를 읽을 수 있지만, 쓰기 작업은 제한받는다.
- 여러 트랜잭션이 데이터를 동시에 읽을 수 있도록 허용하며, 데이터를 수정하는 작업이 이뤄지는 것을 방지
나는 Write Lock을 사용하였다. 물론 Read Lock을 써도 쓰기는 제한받기 때문에 불가능하지 않지만, 재고가 1개가 남았을 때 아직 0으로 업데이트되기 전에 하나 이상의 트랜잭션이 접근하는 것은 불필요하다고 생각하기 때문이다.
(하지만 생각해 보니 재고가 0일 땐 쓰기 작업이 필요 없고 읽기 작업만 필요하기 때문에 오히려 Read Lock을 쓰는 게 나을지도....
왜냐하면 재고가 10개고 요청 수가 10,000개라면 많아봐야 10~15개만 재고 감소 작업을 할 테고 나머지 요청은 읽기만 할 테니까....)
일단 Lock을 적용하는 방법은 JpaRepository에서 어노테이션을 선언해 주고 쿼리를 작성해 주면 된다.
public interface PreOrderStockRepository extends JpaRepository<PreOrderStock, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE) // WRITE -> READ로 바꾸면 Read Lock이 된다.
@Query("SELECT ps FROM PreOrderStock ps WHERE ps.id = :productId")
Optional<PreOrderStock> findByIdWithPessimisticLock(Long productId);
}
그리고 JPA에서 트랜잭션이 필요한 작업을 수행하기 때문에 서비스에서 꼭 @Transactional 어노테이션을 붙여줘야 한다.
@Transactional
public int decreasePreStock(Long productId) {
PreOrderStock stock = preOrderStockRepository.findByIdWithPessimisticLock(productId)
.orElseThrow(() -> new NotFoundException("해당 상품이 없습니다."));
if (stock.getStock() <= 0) {
throw new NotEnoughStock("재고가 부족합니다.");
}
stock.setStock(stock.getStock() - 1);
preOrderStockRepository.save(stock);
return stock.getStock();
}
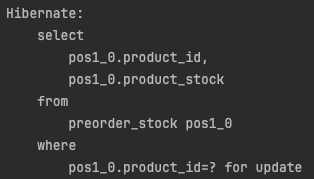
그럼 아래 사진과 같이 update가 되면서 lock이 잘 적용된 것을 볼 수 있다.
2-2. 낙관적 락 (Optimistic Lock)
낙관적 락은 데이터를 읽거나 수정할 때 데이터에 대한 락을 걸지 않고, 데이터를 읽은 후에 수정할 때 해당 데이터가 다른 트랜잭션에 의해 변경되지 않았는지를 확인하는 방식으로 동작한다.
"나중에 충돌이 발생할 것이 아니라고 낙관적으로 가정하고"작업을 수행한다.
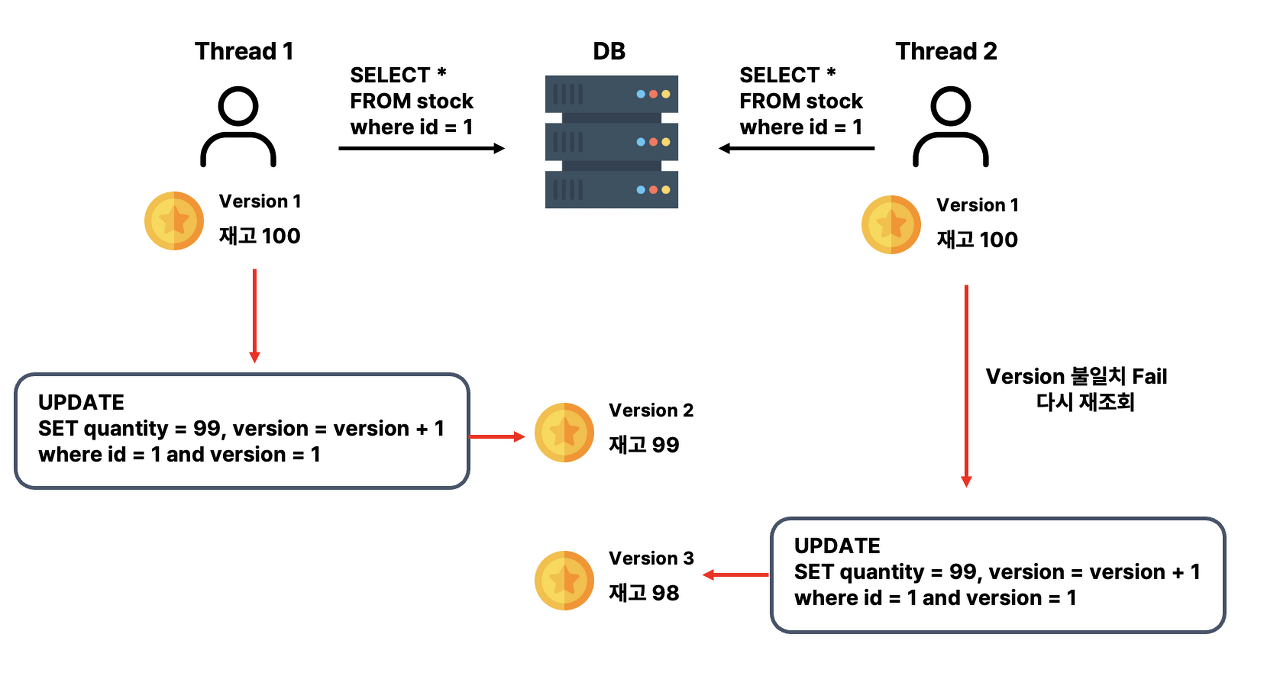
낙관적 락의 적용 방식
- 데이터를 읽을 때는 다른 트랜잭션이 해당 데이터를 수정하지 않을 것이라고 가정하고 데이터를 읽어온다.
- 그리고 데이터를 수정할 때 해당 데이터의 버전 정보를 함께 확인하여 이전에 읽어온 버전과 일치하는지를 검증한다.
- 일치한다면 해당 데이터는 다른 트랜잭션에 의해 변경되지 않았다는 것을 의미하므로 수정 작업을 진행한다.
낙관적 락을 적용하기 위해서는 테이블에 version 칼럼을 삽입하고, 엔티티에도 같은 필드를 작성해야 한다.
(나 같은 경우에는 preorder_stock 테이블과 엔티티에 변경)
테이블을 변경하고 추가로 관리해줘야 하는 이유로 적용하지 않았다.
2-3. 네임드 락 (Named Lock)
네임드 락은 프로그램에서 공유되는 특정 리소스나 데이터에 이름을 지정하여 락을 설정하는 방식이다.
"이름"을 가진 락으로서, 공유되는 리소스에 대한 접근을 제어한다.
주로 다중 스레드 환경에서 공유 자원에 대한 접근을 동기화하는 데 사용된다.
여러 스레드가 공유 데이터에 접근할 때 해당 데이터에 대한 네임드 락을 설정하여 한 번에 하나의 스레드만 해당 데이터를 수정하도록 제한할 수 있다.
또한, 보다 세밀한 제어를 위해 사용될 수 있다. 특정 데이터에 대한 읽기 락과 쓰기 락을 따로 관리하여 동시 읽기와 배타적인 쓰기를 구현할 수 있다.
네임드 락은 주로 분산 락을 사용하려고 할 때 많이 사용하는 방식이다.
나는 네임드 락을 Redis 분산 락과 함께 적용해 보기 위해 MySQL에서는 사용해보지 않았다.
결론
앞서 크게 2가지(작게는 4가지)의 방법을 알아보았다.
synchronized, Lock 중 실무에서 자주 사용하는 방법은 Lock을 사용해서 동시성을 처리하는 방법이다.
Lock의 3가지 종류 중에 대부분이 비관적 락과 낙관적 락을 많이 비교해서 상황에 맞게 사용하고, 네임드 락은 분산락에 사용한다.
그래서 비관적 락과 낙관적 락을 어떤 상황에 사용해 볼지 생각해 보면
충돌이 빈번하게 일어날 것이라고 예상된다면 비관적 락을,
충돌이 빈번하지는 않지만 충돌 발생 시 동시성을 지켜야 한다면 낙관적 락을 추천한다.
참고
https://ksh-coding.tistory.com/125
ChatGPT...
'멋진 개발자 > Java & Spring' 카테고리의 다른 글
| [항해 취업코스] 개발자 취준 기록 9 - 클래스와 인스턴스의 차이 (feat. 객체) (0) | 2024.03.06 |
|---|---|
| [항해 취업코스] 개발자 취준 기록 8 - JVM의 스택과 힙 메모리 영역 (0) | 2024.03.06 |
| [항해 취업코스] 개발자 취준 기록 6 - Java의 컴파일 과정(JVM) (0) | 2024.03.05 |
| [항해 취업코스] 개발자 취준 기록 5 - JVM의 구성과 특징 (0) | 2024.03.05 |
| [항해 취업코스] 개발자 취준 기록 4 - JPA 더티체킹 (0) | 2024.03.05 |