
Redis란?
풀네임에서 알 수 있듯이 Dictionary(key-value) 구조로 데이터를 저장하고 관리하는 서버를 말한다.
Redis 공식 홈페이지(https://redis.io/docs/about/)에서는 Redis를 이렇게 소개하고 있다.
Redis is an open source (BSD licensed), in-memory data structure store used as a database, cache, message broker, and streaming engine.
Redis는 데이터베이스, 캐시, 메세지브로커 및 스트리밍 엔진으로 사용되는 오픈소스, In-Memory 데이터 구조 저장소입니다.
Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams.
Redis는 Strings, Hashes, Lists, Sets, 범위 쿼리가 있는 정렬된 Sets, Bitmaps, Hyperloglogs, 지리공간 index, streams와 같은 데이터 구조를 제공합니다.
Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
Redis는 복제, Lua 스크립팅, LRU 축출, 트랜잭션, 다양한 수준의 디스크 지속성이 내장되어 있으며, Redis Sentinel 및 Redis Cluster를 통한 자동 파티셔닝을 통해 고가용성을 제공합니다.
In-Memory
컴퓨터의 주기억장치인 RAM에 데이터를 올려서 사용하는 방법을 말한다.
RAM에 데이터를 저장하게 된다면 메모리 내부에서 처리가 되므로 데이터를 저장하고 조회할 때 저장장치(HDD, SSD)를 오고 가는 과정을 거치지 않아도 된다.
In-Memory DB인 Redis는 위와 같은 이유로 저장장치에서 데이터를 가져오는 것보다 RAM에서 데이터를 가져오는 속도가 많게는 수백 배 이상 빠르다는 장점이 있다.
하지만 빠른 속도를 자랑하는 대신 용량으로 인해 데이터 유실이 발생할 수 있다는 단점이 있다.
서버의 메모리 용량을 초과하는 데이터를 Redis에서 처리할 경우, 서버 자체에도 문제가 생기며, RAM의 특성인 휘발성에 따라 RAM에 저장되었던 Redis의 데이터들은 유실될 수 있다. 그렇게 때문에 메인 DB로 사용하기에는 무리가 있다.
(하지만 별도의 설정을 통해 데이터의 영속성을 보장할 수 있다.)
Redis의 특징
- Key, Value 구조이기 때문에 쿼리를 사용할 필요가 없습니다 (NoSql)
- 데이터를 디스크에 쓰는 구조가 아니라 메모리에서 데이터를 처리하기 때문에 속도가 굉장히 빠르다.
- Single Threaded로 한 번에 하나의 명령만 처리될 수 있기 때문에 원자성의 특성을 가진다.
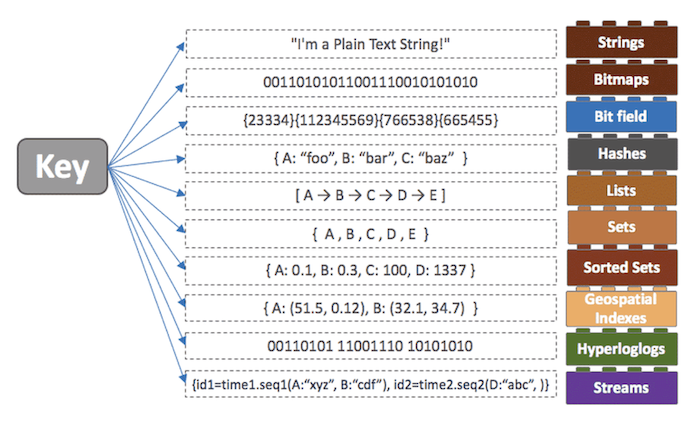
- String, Lists, Sets, Sorted Sets, Hashes 등 다양한 자료 구조를 지원한다.
- Strings : 문자열로, 가장 일반적인 key-value 구조의 형태
- Sets : String의 집합이며 유일한 값들의 모임인 자료구조. 여러 개의 값을 하나의 value에 넣을 수 있다. 게시글의 #tag 같은 곳에 사용될 수 있다.
- Sorted Sets : Sets 자료구조에 score라는 값을 추가로 두어 해당 값을 기준으로 순서를 유지한 구조다. 랭킹 서버 같은 구현에 사용할 수 있다.
- Lists : String 요소의 모음. 순서는 삽입된 수서를 유지하며 기본적인 자료구조로 LinkedList를 사용
- Hashes : 내부에 key-value 구조를 하나 더 가지는 자료구조
Redis의 활용
1. 캐싱 (Caching)
Redis는 데이터 캐싱에 매우 적합한 데이터 저장소이다. 캐싱은 DB나 파일 시스템 등의 느린 데이터 저장소에 대한 접근을 줄이고, 더 빠른 접근을 위해 데이터를 메모리에 저장하는 것을 의미한다.
Redis를 이용한 캐싱은 웹 사이트나 애플리케이션에서 DB 쿼리 등의 불필요한 접근을 줄이고, 빠른 응답 속도를 제공할 수 있다.
2. 세션 저장 (Session Storage)
세션은 웹 애플리케이션에서 사용자 상태를 유지하기 위한 방법이다. Redis를 이용해 세션 데이터를 저장하면, 다수의 서버에서 접근할 수 있는 세션 데이터를 공유할 수 있으며 애플리케이션의 확장성을 높일 수 있다.
3. 메시지 큐 (Message Queue)
Redis는 메시지 큐의 역할을 수행할 수 있다. 메시지 큐는 비동기적인 메시지 처리를 지원하는 소프트웨어 패턴으로, 메시지 발신자(Sender)와 수신자(Receiver) 간의 통신을 통해 데이터 처리를 수행한다.
Redis는 Pub/Sub 기능을 이용하여 메시지 큐를 구현할 수 있으며 높은 처리량과 낮은 지연 시간을 제공할 수 있다.
4. 실시간 채팅 (Real-time Chat)
Pub/Sub 기능을 제공하여 다수의 클라이언트 간의 실시간 메시지 전달을 지원할 수 있다.
5. 랭킹 (Ranking)
Redis는 Sorted Set 구조를 지원하므로 이를 이용하여 사용자나 상품 등의 랭킹을 구현할 수 있다.
Sorted Set은 score라는 값을 추가로 두어 value 간의 랭킹을 저장하고, 조회하는 등 다양한 작업을 수행할 수 있다.
6. 분산 락 (Distributed Lock)
분산 락은 다수의 서버에서 동시에 접근하는 데이터에 대해 동기화를 유지하기 위해 사용되며 싱글 스레드인 Redis를 이용하여 분산 락을 구현하다면 서버에서 안전하게 데이터를 접근할 수 있으며 동시성 문제를 해결할 수 있다.
Redis의 영속성
Redis는 RAM의 데이터를 저장하기 때문에 서버에 장애가 발생할 경우 데이터 유실이 일어날 수 있다. 하지만 이러한 문제를 해결하고 영속성을 보장하기 위해 데이터를 디스크에 저장할 수 있는 방법이 있다.
- RDB (Snapshotting) 방식 :
명시된 간격마다 dataset의 해당 지점의 Snapshot을 수행한다. (Snapshot 찍기) - AOF (Append On File) 방식 :
서버로 수신된 모든 쓰기 작업을 Log 파일에 기록하고 서버 재시작 시 수행돼서 원래의 dataset을 재구축한다. (파일에 의존)
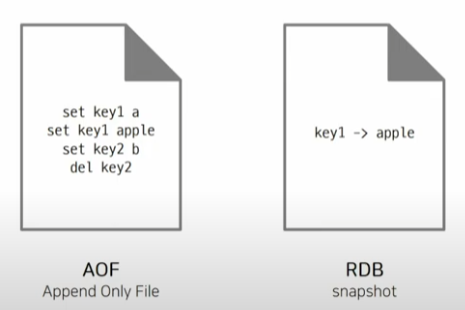
백업 방식은 다음과 같은 상황에 맞춰 사용이 가능하다.
백업은 필요하지만 어느 정도의 데이터 손실이 발생해도 괜찮은 경우에는 RDB 단독 사용.
장애 상황 직전까지의 모든 데이터가 보장되어야 할 경우 AOF 사용
가장 강력한 내구성이 필요한 경우 두 가지 방식을 모두 사용해야 한다. 이러한 이유로 추후에 AOF와 RDB를 하나의 영속성 모델로 통합할 계획을 가지고 있다. (장기적으로....)
Redis 아키텍처
Replication
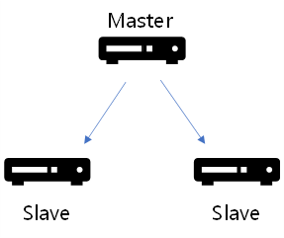
데이터 백업만으로는 소요 시간이나 백업 실패 등 다양한 이유로 장애 대비에 부족하다.
Redis도 RDB처럼 복제를 통해 가용성과 조회 트래픽 분산을 통해 성능을 향상 시킬 수 있다.
Master Node와 Replica Node로 구성되어 Master Node 장애 발생 시 Replica Node를 master로 전환하여 장애 상황애 대처 할 수 있다.
Master 재시작 시 백업이 되어있지 않아서 빈 상태로 있게 되면 Master를 Read 하고 있는 Replica에도 빈 상태가 복제되기 때문에 Master Node에는 백업기능을 무조건 활성화해두어야 한다.
Master Node는 1개만 존재하며, 복제 방식은 비동기 방식이다.
Master 장애 시 수동으로 Replica를 Master로 전환해주어야 한다.
Sentinel
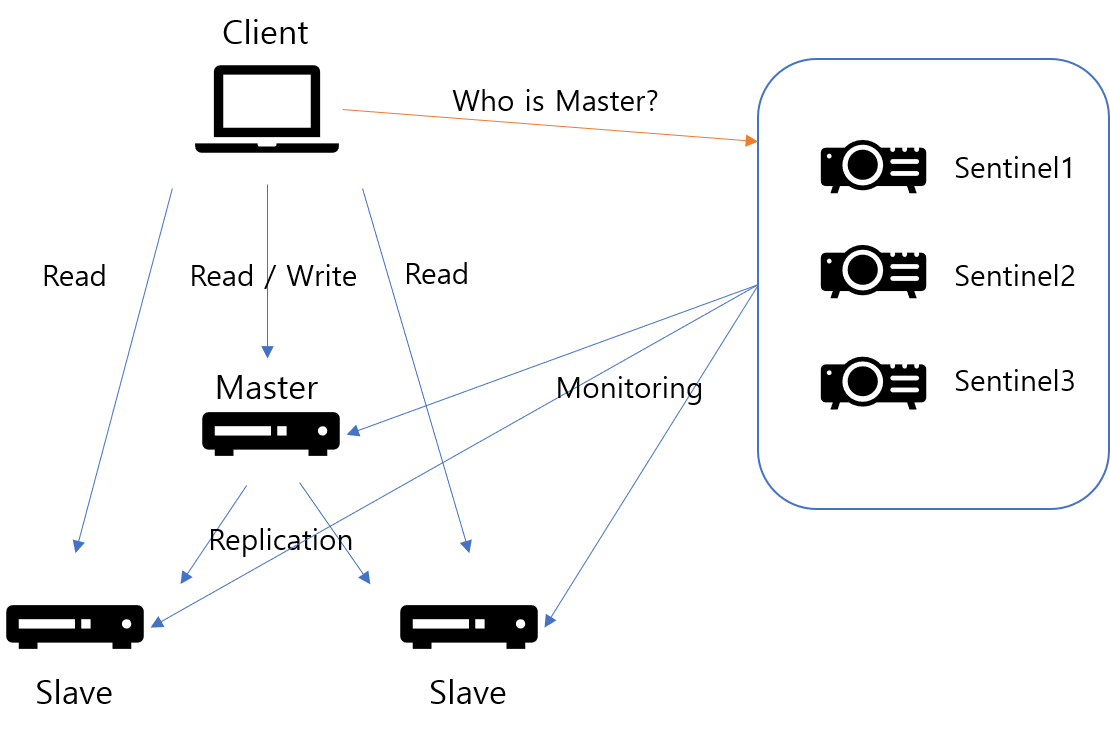
장애 생황에서 Master와 Replica 사이에 수동으로 전환해줘야 하는 작업의 가용성 저하를 해결하기 위해 사용한다.
Sentinel은 Master Node와 Replica Node를 계속 모니터링하면서, 장애 상황이 발생하면 Replica Node를 master로 승격시키는 Auto Failover를 진행한다.
Sentinel의 개수는 홀수여야 하는데, 그 이유는 장애 발생 시 Sentinel 중에 과반 수 이상이 동의를 해서 Auto Failover가 진행돼야 하기 때문이다. (최소 3개)
이를 위해서 애플리케이션은 Master Node나 Replica Node에 직접 연결하지 않고, Sentinel Node와 연결된다.
그리고 Sentinel Node는 애플리케이션에게 현재 Master Node의 IP, Port를 알려준다.
Cluster

Full-mesh구조로 모든 Node가 연결되어서 통신하는 구조이다.
일부 Node의 실패나 통신 단절에도 계속 작동하는 가용성이라는 특징이 있고, 고성능을 보장하면서 선형 확장성을 제공한다. 최소 3개의 Master Node가 필요하며 확장성이라는 특징이 있기 때문에 Node를 추가할 수 있다.
데이터를 여러 Node로 자동분할 하는 기능(샤딩)을 제공하며 Cluster를 구성하는 각 Redis 들 간에 Gossip Protocol을 통해 통신한다.
샤딩(Sharding)
파티셔닝이라고도 불리는데, 데이터를 특정 조건에 따라 분할 저장하는 방법이다. (쓰기 분산)
Ex) 15개의 값이 있으면, Node A : 0 ~ 5 / Node B : 6 ~ 10 / Node C : 11 ~ 15
Gossip Protocol
소문이 퍼지는 것처럼 주변에 있는 일부 Node에만 데이터를 송신하게 되면 Node 간의 데이터 정합성이 시간이 지나면서 확률적으로 맞추어지는 protocol이다.
동기화를 위해 모든 Node들이 서로에게 데이터를 송신하면 같은 데이터를 여러 번 주고받기 때문에 매우 비효율적이다.
여러 데이터를 분할 저장하므로 더 많은 데이터를 저장할 수 있고 더 많은 쓰기 연산 처리가 가능한 장점이 있다.
하지만 애플리케이션의 복잡도가 증가하고 하나의 Node로 요청이 몰리는 경우, 성능확장을 위해 서비스 수정 / 중단이 불가피하다는 단점이 있다.
참고
https://wildeveloperetrain.tistory.com/21
https://velog.io/@hope1213/Redis%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C
https://lifeplan-b.tistory.com/13
'멋진 개발자 > DB' 카테고리의 다른 글
| 개발자 성장 기록 48 - WHERE, HAVING (0) | 2024.04.15 |
|---|---|
| 개발자 성장 기록 47 - DELETE, TRUNCATE, DROP (0) | 2024.04.12 |
| 개발자 취준 기록 31 - Primary Key, Foreign Key (1) | 2024.03.26 |
| 개발자 취준 기록 29 - DDL, DML, DCL (0) | 2024.03.25 |
| [항해 취업 코스] 개발자 취준 기록 28 - 쿼리 최적화, DB 로직 최소화 (0) | 2024.03.22 |